
Why Chunking Matters in 2026
Before diving into the methods, let's understand why chunking remains critical for AI automation:
- Token optimization: Embedding models have token limits. Proper chunking maximizes information density
- Context preservation: Chunks must maintain semantic coherence for accurate retrieval
- Search relevance: The quality of your RAG pipeline directly depends on chunk boundaries
- Cost efficiency: Smaller, targeted chunks reduce API costs and improve response times
With AI agents handling increasingly complex tasks—from customer service via AI voice agents to sophisticated document analysis—chunking has evolved from a simple preprocessing step to a strategic decision that impacts your entire AI automation infrastructure.
Overlapped Chunking: Preserving Context Across Boundaries
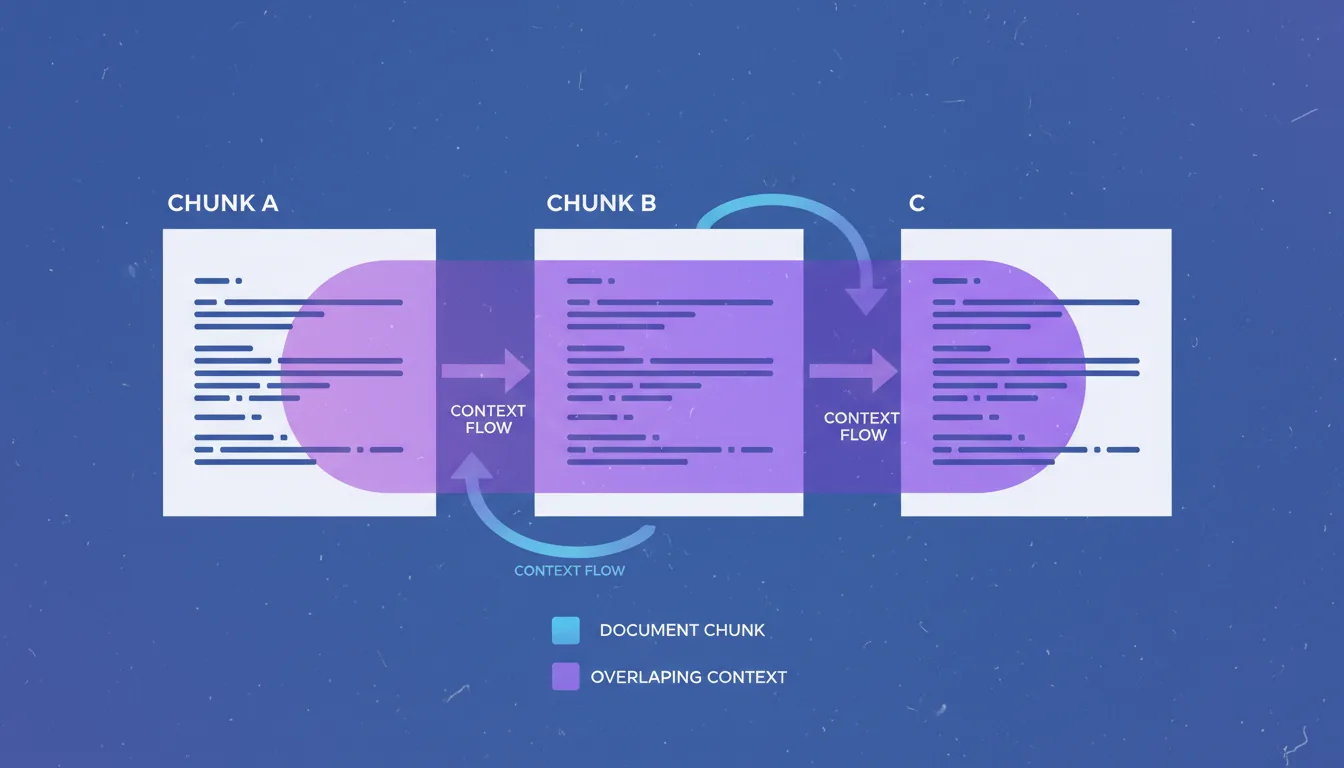
What Is Overlapped Chunking?
Overlapped chunking creates chunks that share a portion of their content with adjacent chunks. Instead of cutting documents at clean boundaries, you intentionally include overlapping sections to ensure no critical context is lost.
How It Works
Document: "The neural network processes input data..." Chunk 1: "The neural network processes input [data...]" Chunk 2: "[data through multiple] layers, each performing..."
When to Use Overlapped Chunking
- Technical documentation with complex terminology
- Legal documents where context is critical
- Code repositories with interdependent functions
- Research papers with continuous logical flow
Semantic Chunking: Intelligence-Based Division
What Is Semantic Chunking?
Semantic chunking uses embeddings and clustering algorithms to identify natural topic shifts in your document, creating chunks that align with semantic boundaries rather than arbitrary character counts.
How It Works
- Split document into sentences or small segments
- Generate embeddings for each segment
- Calculate semantic similarity between adjacent segments
- Create boundaries where similarity drops below a threshold
Implementation Example
from sentence_transformers import SentenceTransformer
def semantic_chunking(text, similarity_threshold=0.5):
sentences = text.split('. ')
model = SentenceTransformer('all-MiniLM-L6-v2')
embeddings = model.encode(sentences)
# Calculate similarity and find boundaries
chunks = []
current_chunk = sentences[0]
for i in range(1, len(sentences)):
similarity = np.dot(embeddings[i-1], embeddings[i])
if similarity < similarity_threshold:
chunks.append(current_chunk)
current_chunk = sentences[i]
else:
current_chunk += '. ' + sentences[i]
return chunksLate Chunking: The 2026 Revolution

What Is Late Chunking?
Late chunking represents the cutting-edge approach in 2026. Instead of chunking before embedding, you embed the entire document first, then use attention-based methods to identify which token spans correspond to meaningful chunks.
The Innovation
Traditional
Document → Chunk → Embed each chunk → Store
Late Chunking
Document → Embed entire → Attention boundaries → Store
Implementation Example
from transformers import AutoModel, AutoTokenizer
def late_chunking(model_name, text, num_chunks=5):
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
# Encode entire document
inputs = tokenizer(text, return_tensors='pt', truncation=False)
outputs = model(**inputs)
# Use attention weights to identify chunk boundaries
attention = outputs.attentions[-1][0].mean(dim=0)
token_indices = torch.argsort(attention, descending=True)[:num_chunks * 50]
# Extract chunks based on boundaries
return [tokenizer.decode(inputs['input_ids'][0][start:end])
for start, end in boundaries]Comparison: Which Method Should You Choose?
| Feature | Overlapped | Semantic | Late |
|---|---|---|---|
| Complexity | Low | Medium | High |
| Compute Cost | Low | Medium | High |
| Context Preservation | Good | Very Good | Excellent |
| Retrieval Precision | Medium | High | Very High |
| Best For | Simple documents | Mixed content | Complex RAG |
Decision Matrix
Choose Overlapped Chunking if:
You need quick implementation, documents are relatively simple, or you have limited compute resources.
Choose Semantic Chunking if:
Your documents have clear topic shifts, you need balance between complexity and quality, or you're building a production RAG system.
Choose Late Chunking if:
Retrieval accuracy is critical, you have complex multi-part documents, or you're working on cutting-edge AI automation projects.
Implementation Best Practices
1. Test Multiple Approaches
def evaluate_chunking_method(method, test_cases):
results = []
for doc in test_cases:
chunks = method(doc)
retrieval_accuracy = test_retrieval(chunks)
results.append(retrieval_accuracy)
return np.mean(results)2. Optimize Chunk Size by Document Type
| Document Type | Recommended Size | Method |
|---|---|---|
| Technical Docs | 500-800 tokens | Semantic |
| Legal Documents | 300-500 tokens | Late + Overlap |
| Support Articles | 400-600 tokens | Semantic |
| Code | 200-400 tokens | Overlapped |
Watch the Full Breakdown
We covered all three chunking methods in detail on our YouTube channel. Watch the video below for a visual walkthrough of overlapped, semantic, and late chunking with real examples and a comparison chart:
Conclusion
As AI automation continues to evolve in 2026, the importance of sophisticated document chunking cannot be overstated. Whether you choose the simplicity of overlapped chunking, the intelligence of semantic chunking, or the cutting-edge approach of late chunking, the key is to match your method to your specific use case.
At TecAdRise, we help businesses leverage the latest in AI automation technology—from intelligent RAG systems to AI voice agents that transform customer interactions. The right chunking strategy is foundational to building AI systems that truly understand and serve your users.
Resources
Ready to Supercharge Your AI Automation?
Contact TecAdRise today and discover how our expertise in cutting-edge AI solutions can transform your business.
Get Started

