Beyond Simple Vector Search
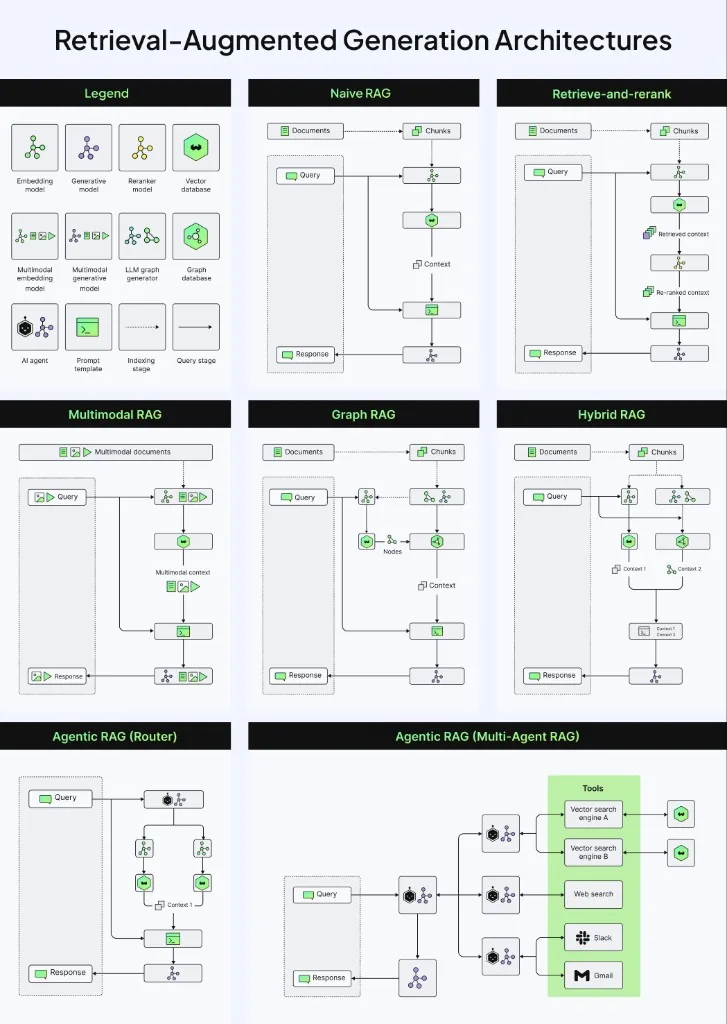
When most people hear "RAG" (Retrieval-Augmented Generation), they picture a straightforward process: chunk documents, create embeddings, store them in a vector database, and retrieve similar chunks when a query comes in. But this vanilla approach is just the beginning. In production environments, RAG has evolved into at least seven distinct architectures, each designed for specific challenges and use cases.
Choosing the wrong architecture means you are either overengineering a simple problem or underserving a complex one. Understanding these patterns helps you build AI systems that actually work for your specific requirements, whether you are building an internal knowledge base, a customer-facing chatbot, or a sophisticated research assistant.
This guide walks through each architecture progressively, from the simplest to the most sophisticated. By the end, you will know which approach fits your use case and how to evaluate whether you need to level up.
1. Naive RAG: The Vanilla Approach
Naive RAG is where everyone starts. It is the textbook implementation you see in most tutorials and getting-started guides. The process is straightforward:
- Document ingestion: Your documents get chunked into manageable pieces (typically 500-1000 tokens)
- Embedding generation: Each chunk is converted to a vector using an embedding model (OpenAI, Cohere, or open-source alternatives)
- Vector storage: Embeddings are stored in a vector database (Pinecone, Weaviate, Chroma, etc.)
- Query processing: When a user asks a question, the query is embedded using the same model
- Similarity search: The system retrieves the most similar chunks based on cosine similarity or other distance metrics
- Response generation: Retrieved chunks are passed to an LLM along with the original query to generate a response
When Naive RAG works well:
- Your documents are relatively uniform in structure and topic
- Queries are straightforward and directly match document content
- You need a quick proof of concept or MVP
- Your knowledge base is small to medium-sized (thousands of documents)
When Naive RAG falls short:
- Semantic similarity does not always align with what the user actually needs
- Complex queries require reasoning across multiple documents
- Your content includes relationships and entities that matter for answering questions
2. Retrieve-and-Rerank: Precision Through Re-scoring
Retrieve-and-Rerank adds a crucial step after initial retrieval. Instead of trusting the vector similarity scores completely, a reranker model re-scores and reorders the results based on actual relevance to the query.
How it works:
- Perform initial retrieval using vector search (same as Naive RAG)
- Retrieve more candidates than you need (e.g., top 20 instead of top 5)
- Pass query-document pairs to a cross-encoder reranker model
- Reranker scores each pair based on relevance, not just similarity
- Reorder results by reranker scores and take the top N
The key insight is that embedding-based similarity captures whether two texts are semantically similar, but a cross-encoder can evaluate whether a specific document actually answers a specific question. These are different tasks.
Popular reranker options:
- Cohere Rerank API (managed service)
- Jina AI Reranker
- Open-source cross-encoders (BAAI/bge-reranker, cross-encoder/ms-marco-MiniLM)
When to use Retrieve-and-Rerank:
- You notice that retrieved documents are semantically similar but not actually answering the question
- Precision matters more than speed (reranking adds latency)
- You have queries that require nuanced understanding of relevance
3. Multimodal RAG: Beyond Text
Multimodal RAG extends retrieval to handle more than just text. Images, videos, audio, and diagrams can all become part of your knowledge base. This architecture uses multimodal embedding models that encode different data types into the same vector space.
Key components:
- Multimodal embeddings: Models like CLIP, ImageBind, or proprietary APIs that can embed text and images into a shared space
- Content extraction: OCR for documents, transcription for audio, frame extraction for video
- Unified retrieval: A single query can retrieve relevant text chunks, images, or other media
- Multimodal generation: LLMs that can process and reference multiple modalities in their responses
Use cases for Multimodal RAG:
- Technical documentation with diagrams and screenshots
- E-commerce product catalogs with images
- Medical records with imaging data
- Training materials combining video, slides, and transcripts
- Architecture documentation with system diagrams
Implementation considerations:
- Storage requirements increase significantly with media files
- Embedding costs are higher for multimodal models
- Metadata becomes critical for filtering and organizing different content types
4. Graph RAG: Capturing Relationships
Graph RAG fundamentally changes how you think about your knowledge base. Instead of treating documents as isolated chunks, this approach builds a knowledge graph that captures relationships between entities, concepts, and documents.
The Graph RAG process:
- Entity extraction: Identify entities (people, companies, products, concepts) in your documents
- Relationship extraction: Determine how entities relate to each other
- Graph construction: Build a graph where nodes are entities and edges are relationships
- Graph-enhanced retrieval: Traverse the graph to find relevant context that vector similarity alone would miss
- Context assembly: Combine graph-based context with traditional chunk retrieval
Why graphs matter:
Consider a query like "What products does company X sell that compete with company Y?" Vector search might retrieve documents mentioning each company, but it cannot reason about the competitive relationship. A knowledge graph explicitly captures these connections.
Graph database options:
- Neo4j (most mature, excellent query language)
- Amazon Neptune
- ArangoDB
- Weaviate (combines vector and graph capabilities)
When Graph RAG excels:
- Questions involve relationships between entities
- Your domain has well-defined ontologies or taxonomies
- Multi-hop reasoning is required (A relates to B relates to C)
- You need explainable retrieval paths
5. Hybrid RAG: Combining Vector and Graph
Hybrid RAG combines the strengths of vector search with structured relationship mapping from knowledge graphs. This architecture recognizes that some queries need semantic similarity while others need structured relationship traversal.
How Hybrid RAG works:
- Dual indexing: Documents are both embedded in vector space and parsed into a knowledge graph
- Query analysis: Determine whether the query needs vector search, graph traversal, or both
- Parallel retrieval: Execute vector search and graph queries simultaneously
- Result fusion: Combine and deduplicate results from both approaches
- Context ranking: Use a unified scoring function to rank the combined results
The key insight: Vector search understands the "what" (semantic content), while graphs understand the "how" (connections and relationships). Together, they provide richer context than either alone.
Implementation approaches:
- Weaviate with graph features: Built-in support for both vector and graph queries
- Neo4j + vector database: Separate systems coordinated by your application logic
- LlamaIndex with both retrievers: Orchestration layer handling both approaches
6. Agentic RAG (Router): Intelligent Query Routing
Agentic RAG with a router pattern introduces intelligence into the retrieval decision itself. Instead of a single retrieval path, an AI agent decides which knowledge source to query based on the user's question.
How the router works:
- Query classification: An LLM analyzes the incoming query to understand what kind of information is needed
- Source selection: Based on the classification, the router selects one or more knowledge sources
- Targeted retrieval: Each selected source is queried with optimized parameters
- Result aggregation: Results from multiple sources are combined and processed
Example router decisions:
- "What is our return policy?" → Route to internal documentation vector DB
- "What are today's headlines?" → Route to web search API
- "Show me similar products" → Route to product catalog with image search
- "What did the CEO say about expansion?" → Route to meeting transcripts and press releases
Benefits of routing:
- Reduced latency by avoiding unnecessary searches
- Better results by using specialized retrieval for each source type
- Cost optimization by not querying expensive APIs when cheaper sources suffice
- Ability to integrate diverse knowledge sources without a unified index
7. Agentic RAG (Multi-Agent): Orchestrated Intelligence
Multi-Agent RAG is the most sophisticated architecture. Multiple specialized agents work together, each with access to different tools and databases. They coordinate to answer complex queries that require information from multiple domains.
Multi-Agent architecture components:
- Orchestrator agent: Breaks down complex queries, delegates to specialists, assembles final response
- Specialist agents: Domain-specific agents optimized for particular knowledge areas
- Tool agents: Agents with access to external APIs, databases, or computation tools
- Verification agents: Agents that fact-check and validate information before final response
Example multi-agent workflow:
User asks: "Compare our Q4 sales performance to competitors and suggest improvements based on market trends."
- Orchestrator identifies three sub-tasks: internal data retrieval, competitor analysis, market research
- Internal data agent queries the sales database and CRM
- Competitor agent searches public filings, news, and industry reports
- Market research agent accesses trend data and analyst reports
- Analysis agent synthesizes findings and generates recommendations
- Orchestrator assembles the final response with citations
When Multi-Agent RAG is justified:
- Queries regularly span multiple domains or data sources
- Different knowledge sources require different access patterns or credentials
- Complex reasoning and verification are required
- You need audit trails showing how information was gathered and synthesized
Challenges to consider:
- Significantly higher latency and cost per query
- Complex debugging and monitoring requirements
- Potential for agents to go off-track without proper guardrails
- Need for robust error handling when individual agents fail
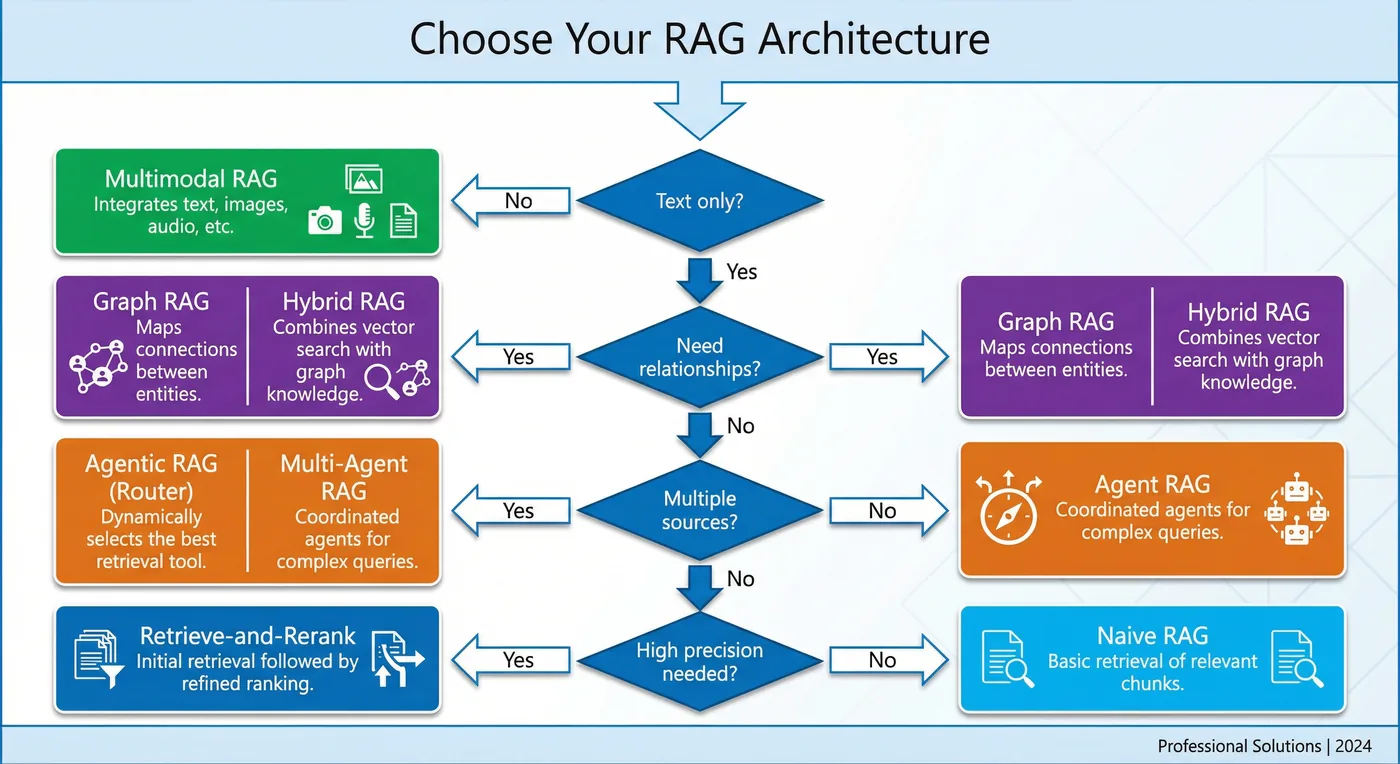
Choosing the Right Architecture
The architectures get progressively more powerful but also more complex to implement and maintain. Start simple and level up only when your use case demands it.
| Architecture | Complexity | Best For | Avoid When |
|---|---|---|---|
| Naive RAG | Low | MVPs, simple Q&A, uniform documents | Precision matters, complex queries |
| Retrieve-and-Rerank | Low-Medium | Improved precision without major changes | Latency-critical applications |
| Multimodal RAG | Medium | Image-heavy content, technical docs | Text-only knowledge base |
| Graph RAG | Medium-High | Entity relationships, multi-hop reasoning | Unstructured content without clear entities |
| Hybrid RAG | High | Mixed query types, complex domains | Simple use cases, limited resources |
| Agentic Router | High | Multiple diverse sources, varied queries | Single knowledge source |
| Multi-Agent | Very High | Complex research, cross-domain synthesis | Cost-sensitive, simple queries |
Decision framework:
- Start with Naive RAG for your initial prototype
- Add Reranking if retrieval quality is the bottleneck
- Consider Multimodal if you have significant non-text content
- Explore Graph RAG if relationship-based queries are common
- Implement Hybrid when you need both semantic and structural understanding
- Deploy Agentic patterns only when simpler approaches hit their limits
Conclusion
RAG has evolved far beyond the simple "embed and retrieve" pattern. Understanding these seven architectures gives you a toolkit for building AI systems that match your actual requirements rather than defaulting to the most hyped or simplest approach.
The key is progressive complexity: start simple, measure what is working and what is not, and level up your architecture when you have concrete evidence that you need more sophistication. Every step up the complexity ladder adds cost, latency, and maintenance burden, but also unlocks capabilities that simpler approaches cannot provide.
At TecAdRise, we help businesses implement production-grade RAG systems matched to their specific use cases. Whether you need a straightforward knowledge base or a sophisticated multi-agent system, we design and deploy architectures that actually work, without overengineering or vendor lock-in.
Resources
Need Help Choosing Your RAG Architecture?
Contact TecAdRise for a technical assessment. We will analyze your requirements and recommend the right architecture for your use case.
Get Started

