What Is RAG and Why It Matters
Large language models are impressive, but they have a critical flaw: they only know what they were trained on. Ask a model about something that happened last month, something in your internal documents, or a specific policy in your company handbook, and it either makes something up or admits it does not know.
Retrieval-Augmented Generation (RAG) was designed to fix this. Instead of relying solely on trained parameters, RAG connects the model to an external knowledge source, typically a vector database. When a user asks a question, the system retrieves the most relevant documents and passes them to the model as context. The model then generates an answer grounded in that retrieved evidence.
The result is a system that is more factually accurate, easier to update, and far cheaper to maintain than repeatedly fine-tuning a model on new data. RAG became the dominant architecture for enterprise AI applications from 2023 onward because of these practical advantages.
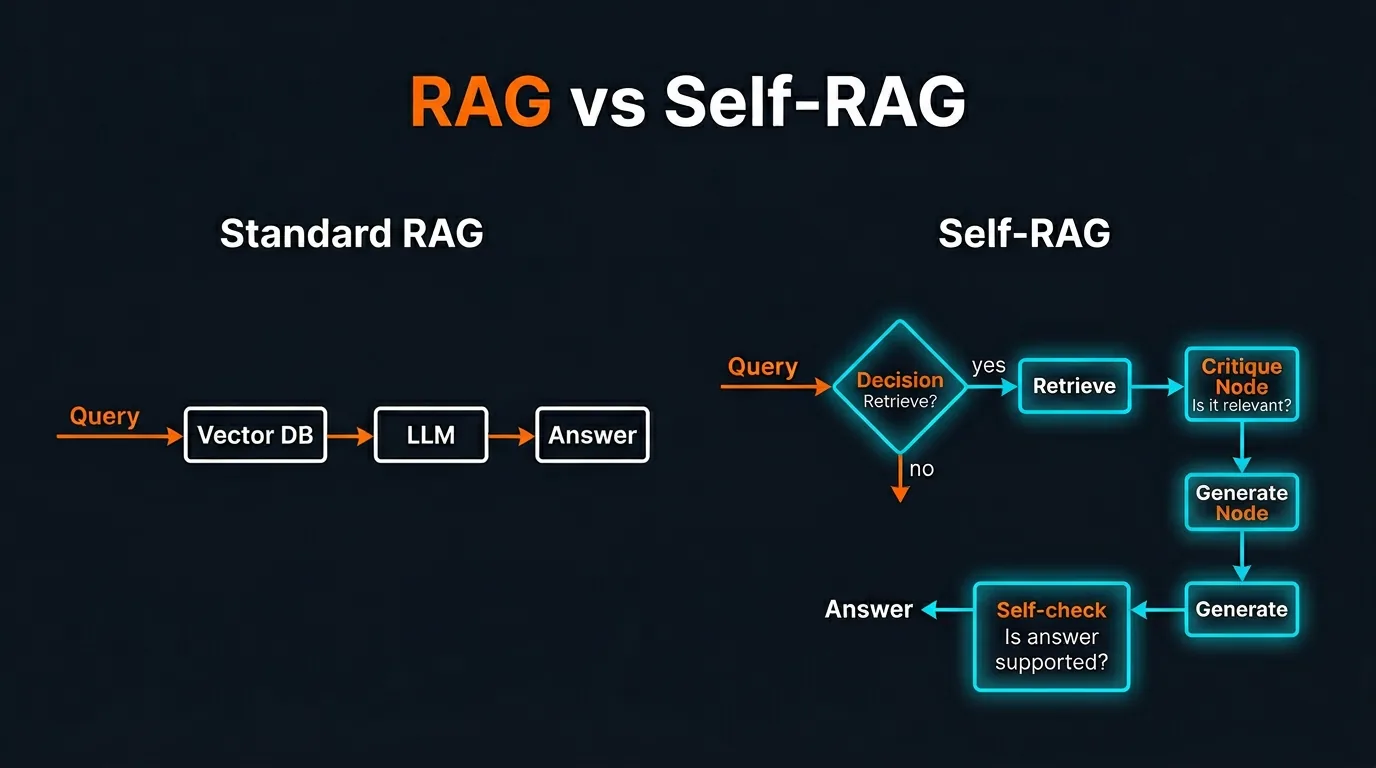
The Problem with Standard RAG
Standard RAG has one fundamental design decision baked in: it always retrieves. Every single query triggers a vector search, whether the question actually needs external context or not.
Ask a model "what is 2 + 2?" and a standard RAG pipeline will dutifully search its knowledge base, find some marginally related documents, and pass them in as context before answering. This is wasteful, slower, and can actually hurt answer quality by introducing irrelevant context that confuses the model.
- Unnecessary retrieval: Simple factual questions do not need external context at all.
- No self-correction: If the retrieved documents are wrong or irrelevant, standard RAG has no mechanism to detect this.
- No output validation: Once the model generates an answer, nothing checks whether that answer is actually supported by the retrieved evidence.
These limitations are acceptable for simple use cases, but they become serious problems in high-stakes applications where accuracy matters, such as medical, legal, or financial contexts.
What Is Self-RAG
Self-RAG is an advanced framework that adds a layer of autonomous reasoning on top of standard RAG. Instead of always retrieving, the model first decides whether retrieval is even necessary. After retrieving, it evaluates whether what it found is relevant. After generating, it checks whether the output is actually supported by the evidence.
This self-critical behavior is what makes Self-RAG significantly more reliable than its predecessor. The model is not just a passive text generator. It acts as its own quality control layer throughout the entire pipeline.
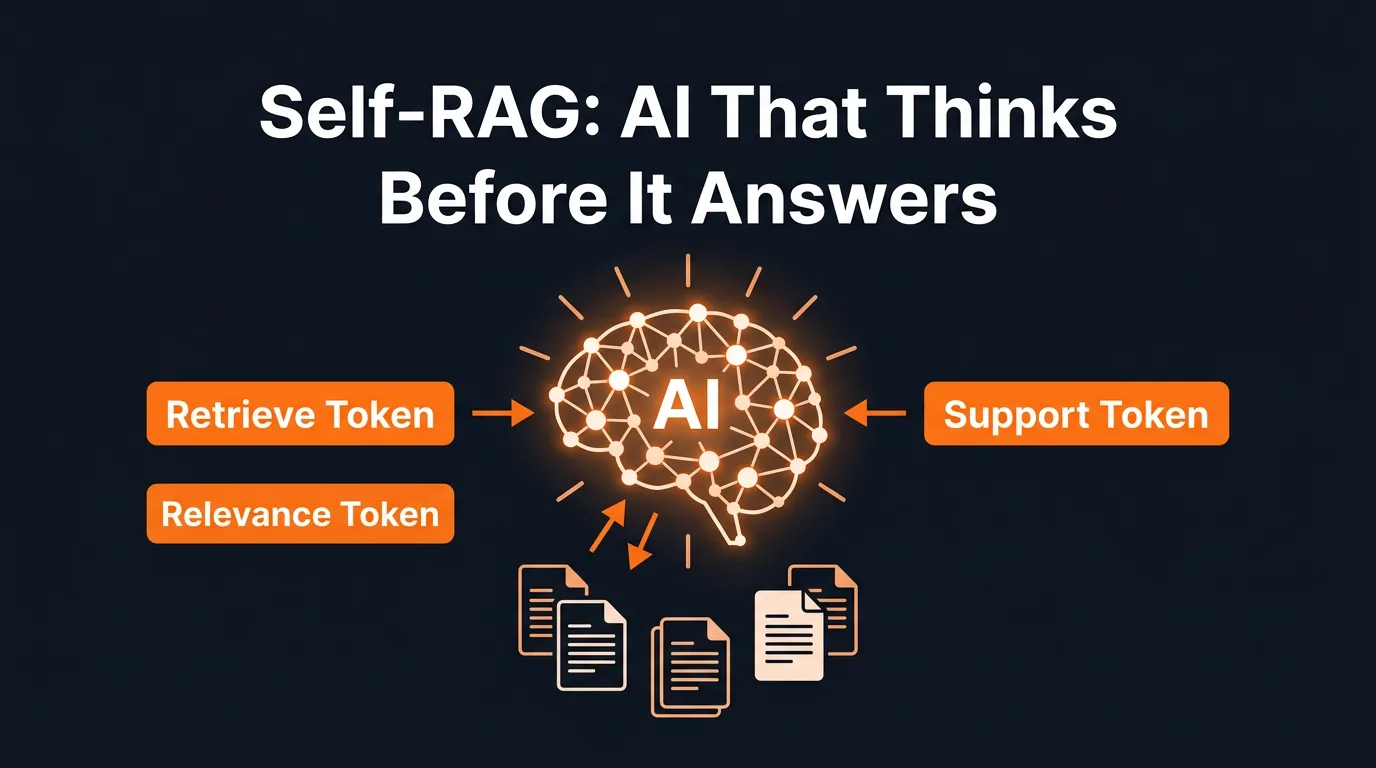
How Reflection Tokens Work
The mechanism behind Self-RAG is a set of special markers called reflection tokens. These are not retrieved from external sources. They are generated by the model itself as part of the reasoning process. There are three key types:
- Retrieve token: The model generates this to decide "do I need to look something up for this query, or can I answer from my own knowledge?" If the answer is no, it skips retrieval entirely.
- Relevance token: After retrieving documents, the model evaluates each one. "Is this document actually relevant to the question being asked?" Irrelevant documents are discarded before generation.
- Support token: After generating an answer, the model checks "is this answer actually supported by the evidence I retrieved?" If the answer is not grounded in the retrieved content, the model flags it or revises it.
This three-stage self-evaluation dramatically reduces hallucinations and improves the reliability of generated answers compared to standard RAG.
Agentic RAG vs Linear RAG
Both standard RAG and Self-RAG follow a relatively linear process: receive query, retrieve documents, generate answer. Agentic RAG breaks this linearity entirely.
In an agentic RAG system, the model can plan a multi-step retrieval strategy. It might retrieve from one source, evaluate the results, decide it needs more information from a different source, retrieve again, synthesize across multiple documents, and then generate a final answer. This kind of autonomous planning enables far more sophisticated reasoning than any linear pipeline.
- Linear RAG: One retrieval step, one generation step, done.
- Self-RAG: Decides if retrieval is needed, critiques retrieved content, validates output quality.
- Agentic RAG: Multi-step planning, multiple retrieval sources, dynamic strategy based on intermediate results.
The right architecture depends on your use case. For most business applications, Self-RAG offers the best balance of accuracy and cost. Agentic RAG is better suited to complex research tasks where a single retrieval pass is insufficient.
RAG vs Fine-Tuning: Why RAG Wins for Most Use Cases
A common question is whether to use RAG at all, or simply fine-tune the base model on domain-specific data. Fine-tuning embeds knowledge directly into the model weights, which makes it very fast at inference time. But it has serious practical drawbacks:
- Cost: Fine-tuning a large model costs thousands of dollars and must be repeated whenever your knowledge base changes.
- Freshness: Fine-tuned models cannot be updated in real time. RAG pulls from a live knowledge base on every query.
- Transparency: With RAG, you can see exactly which documents the model used to generate an answer. With fine-tuning, the knowledge is opaque inside the weights.
- Verifiability: RAG answers can be traced back to source documents. Fine-tuned answers cannot.
For most business applications, RAG (and especially Self-RAG) is the more cost-effective, maintainable, and reliable choice. Fine-tuning makes sense only when you need to change the model's behavior or style, not just its knowledge.
Watch the Full Breakdown
We covered this topic in full detail on our YouTube channel. Watch the video below for a visual walkthrough of Standard RAG, Self-RAG reflection tokens, and Agentic RAG with real examples:
Conclusion
Standard RAG was a major step forward for grounding AI in verifiable knowledge. Self-RAG takes it further by giving the model the ability to reason about when to retrieve, whether what it retrieved is useful, and whether its own output can be trusted. Agentic RAG extends this into full multi-step planning.
If you are building AI systems where accuracy matters, understanding these distinctions is not optional. The difference between a standard RAG pipeline and a Self-RAG pipeline can be the difference between an AI assistant that confidently gives wrong answers and one that knows when to say "I need to check that."
Resources
Want to Build a Reliable AI System for Your Business?
TecAdRise designs and deploys RAG-based AI automation for small businesses. From knowledge bases to AI agents that actually fact-check themselves.
Get a Free Demo

